production system |
||
|
|
system diagram 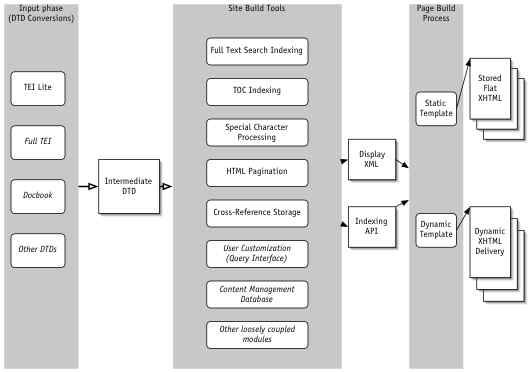
Description and issuesThis diagram shows the architecture of a complete industrial-grade document preparation system. Input DTDs vary widely, but are frequently quite similar, as publishers and other document preparers generally use existing DTDs as a starting point, even if they have created their own customized version. An intermediate DTD that represents document objects in a relatively uniform way allows generic processing modules to be used for common production tasks like table of contents management, editorial indexing (similar to "back of the book" indexes you may be familiar with), full text indexing, and cross-reference management. In the course of conversion from a publisher DTD, information can be replicated into several markup objects, each subjected to different processing. Once the intermediate DTD has been processed by the site-building tools, pages are generated in a "display XML format" where each XML document corresponds to a single web page, and the data within that document can then be turned into HTML easily. Sometimes the pages will contain dynamic elements calculated by the server at the moment of page delivery to the user, in that case, the templates must be executed every time a page is fetched. Many times the content of a page will be completely static, in which case there are 3 common strategies for rendering the page: One is to render the page in batch process at publication time and server the result directly with Apache or another server. This is the fastest method of delivery, but the publication process can be quite slow. Design updates will also require the complete re-generation of the site, increasing the impact of the slower publication process. Another method is to generate all pages dynamically. This makes the publication process much less important: site-building is only required when the input changes (generally not that frequent); furthermore, if the site building process can be made incremental (by tracking input dependencies), further efficiencies are possible. Dynamic generation of pages (especially pages that don't change frequently) is very expensive at delivery time, because of the CPU and memory requirements of templating engines. The most efficient method, of course, is to use a semi-dynamic caching technique, where the outputs of site processing are used by a dynamic generation process the first time they are accessed, but the results are then saved to be delivered directly on future accesses. While this method has the flexibility of dynamic generation, and comes close to the delivery speed of page compilation (minus the small overhead of cache checking), it is not perfect. When design or content changes are made, the caches must be flushed, but under load, the cost of re-compiling the pages on the site may be considerable and lead to performance problems. It is possible to track the dependencies of output pages on both templates and source documents, but this introduces complexity and the concomitant chance of bugs. Bugs in cache and dependency code are often hard to fix because programmers often end up debugging code that isn't being executed. |
|